Machine Learning per PM: Un Corso Intensivo Essenziale

L'Intelligenza Artificiale è probabilmente l'argomento più caldo nel mondo della tecnologia in questo momento.
Ci sono prodotti guidati dall’IA che stanno diventando unicorni o che stanno ottenendo centinaia di milioni in finanziamenti di venture capital. Esistono inoltre famosi leader di prodotto che guidano questi prodotti basati su IA, che seguiamo e da cui impariamo.
Molti product manager desiderano beneficiare di questa incredibile tecnologia, guidando un prodotto IA o aggiungendo funzionalità di intelligenza artificiale ai prodotti esistenti. Se anche tu fai parte di questa categoria, questo articolo è dedicato a te.
Ho creato diversi prodotti di intelligenza artificiale e sono qui per aiutarti a comprendere meglio questa tecnologia e a sfruttarla al massimo.
Che cos'è il Machine Learning?
Il machine learning è una disciplina che si concentra sulla creazione di algoritmi e software in grado di "apprendere" dalle informazioni che forniamo ed eseguire efficacemente compiti specifici come risultato di questo addestramento.
Il termine e il campo stesso sono sorprendentemente antichi — risalgono al 1959, quando Arthur Samuel di IBM (uno dei principali scienziati informatici dell'epoca) lo coniò nel suo lavoro "Some Studies in Machine Learning Using the Game of Checkers."
Nonostante i suoi 60 anni di storia, però, il machine learning è diventato popolare solo nell’ultimo decennio grazie all’enorme aumento della potenza di calcolo, in particolare grazie alle GPU.
Ma cosa c’entra il machine learning con l’intelligenza artificiale? Chiarito questo aspetto, vediamo come proseguire.
Machine Learning (ML) vs Intelligenza Artificiale (AI)
Tutti usano i termini “machine learning” e “intelligenza artificiale” come sinonimi per riferirsi ai software intelligenti in grado di riconoscere oggetti nelle immagini, scrivere poesie e generare risposte impressionanti a richieste dettagliate.
Tuttavia, l’intelligenza artificiale è il concetto più ampio che comprende le macchine con capacità di percezione e ragionamento, mentre il machine learning è una sua sottobranca che si focalizza sui software in grado di apprendere.
Ora che abbiamo chiarito i termini, vediamo come queste macchine apprendono e quali sono i principi di funzionamento.
Come funziona il Machine Learning

Per comprendere il machine learning, bisogna innanzitutto esaminarne la forma più diffusa — le reti neurali profonde (deep learning).
Una rete neurale è una struttura scritta in codice che cerca di replicare il funzionamento di un cervello biologico. Per gli esseri umani e altre creature viventi, il cervello è una rete complessa di neuroni (cellule nervose) connessi tra loro, dove un impulso da una cellula ne attiva un’altra e l’informazione si diffonde lungo la rete di neuroni.
Non credo di essere la persona giusta per spiegare la biologia (fallirei miseramente), quindi mi concentrerò sulla tecnologia.
Le reti neurali nel software hanno un aspetto simile a questo:
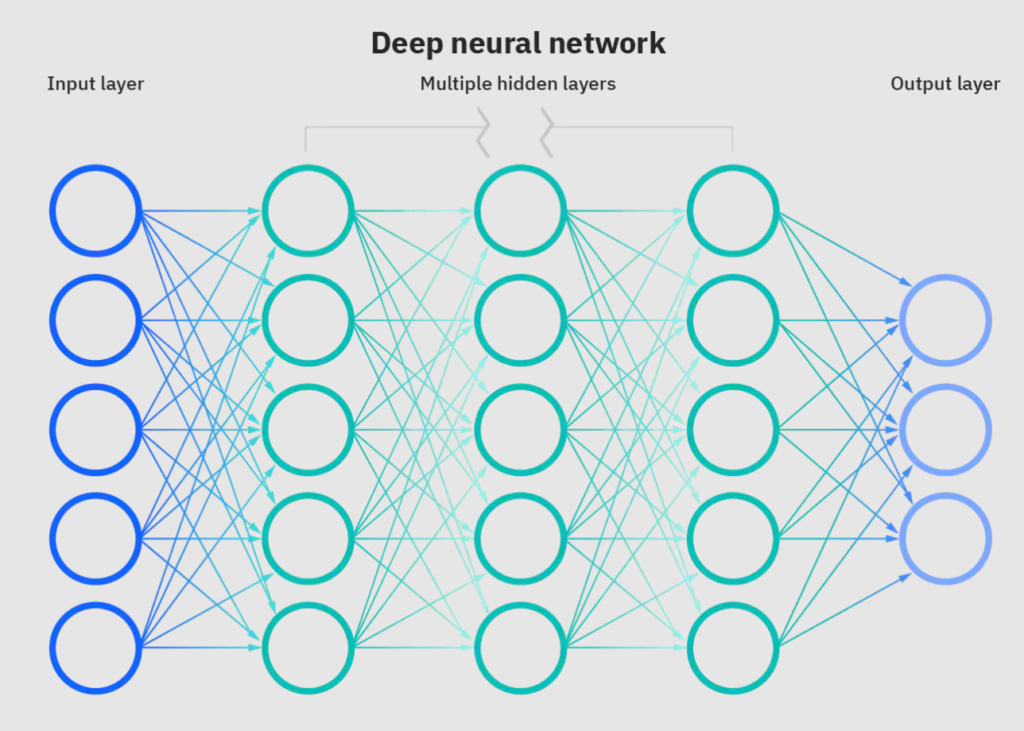
Ogni cerchio qui rappresenta un singolo neurone. Nel codice, un neurone è semplicemente una funzione che può ricevere un certo tipo di informazione, elaborarla e passare il risultato al neurone successivo.
Nota: questa è una semplificazione rispetto al processo reale. Per maggiori dettagli, puoi guardare la straordinaria lezione video sulle reti neurali sul canale YouTube 3blue1brown, dove vengono spiegati anche i concetti matematici alla base di questa tecnologia.
Come possiamo vedere nell'immagine sopra, i neuroni sono organizzati in livelli. Le reti neurali di solito hanno tre tipi di livelli:
- Il livello di input, che si occupa di ricevere informazioni dal mondo esterno.
- I livelli nascosti elaborano queste informazioni, ciascuno processando un singolo aspetto di esse.
- Il livello di output restituisce il risultato elaborato al mondo esterno.
Ora capiamo il significato di questi livelli con un esempio semplice. Immagina di voler far riconoscere a una rete neurale un animale in una foto. Per questo hai ideato una rete neurale composta da sei livelli che funzioneranno nel modo seguente:
- Strato di input che acquisirà piccoli segmenti della foto dell’animale e li passerà al primo strato nascosto.
- Il primo strato nascosto cercherà di individuare forme di base (ad esempio, linee rette) in ogni segmento e passerà queste informazioni al secondo strato.
- Il secondo strato combinerà poi alcune di queste linee in forme geometriche di base (ad esempio, cerchi, semicirconferenze, ecc.) e le passerà al terzo strato.
- Il terzo strato creerà quindi forme più complesse a partire da queste forme geometriche.
- Il quarto strato combinerà tutte le forme create in precedenza e ricaverà un contorno dell’animale.
- Lo strato di output, infine, fornirà il tipo di animale che ha riconosciuto dalla forma.
Visivamente, apparirà in questo modo.
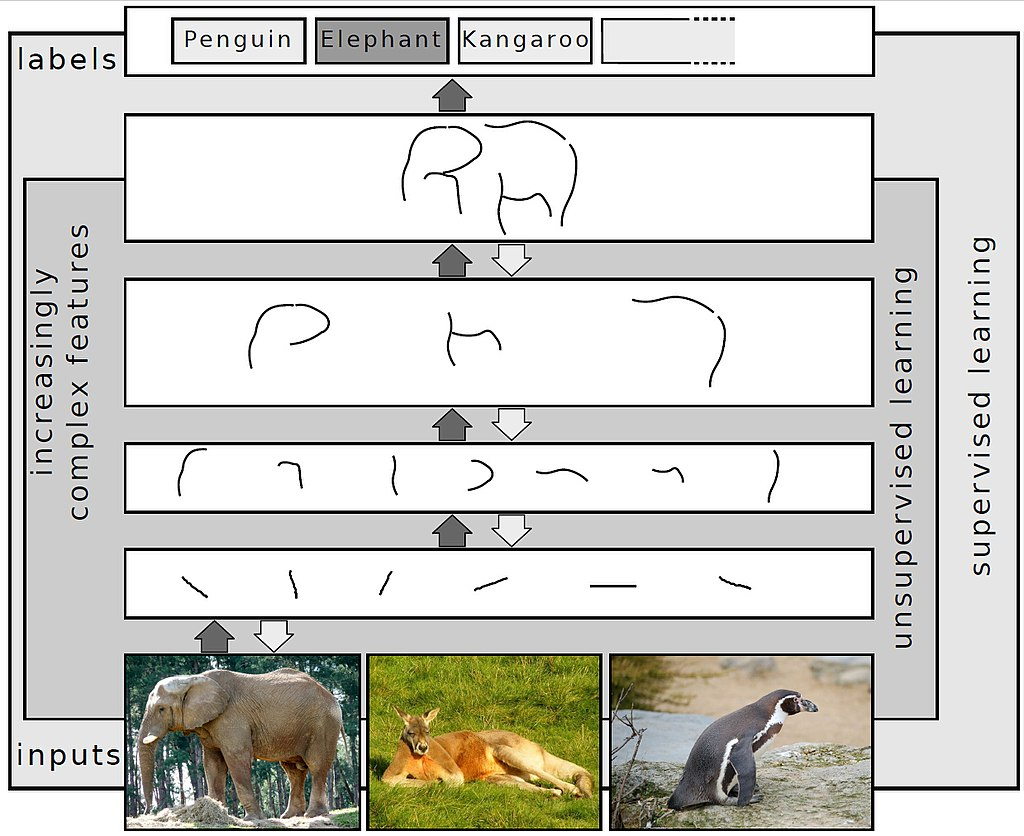
Osservando il processo sopra, potresti chiederti come fanno gli ingegneri AI a far riconoscere a questi strati le forme e a indovinare l’animale nell’immagine, giusto? Beh, lo fanno "addestrando" la rete neurale a svolgere il suo compito.
Per addestrare la rete, gli ingegneri AI le forniranno un set di input insieme ai rispettivi output corretti. Nel nostro caso, saranno diverse immagini di animali come input e queste stesse immagini con il tipo di animale corretto come output.
Poiché la tua rete dispone delle risposte corrette, si aggiusterà continuamente (i parametri che ogni neurone passa agli altri) finché le sue risposte non saranno molto simili a quelle corrette che abbiamo fornito.
Nella realtà, la tua rete non sarà mai accurata al 100% nelle sue risposte e ci sarà sempre un certo grado di errore da considerare. La buona notizia è che in realtà non vuoi che siano davvero al 100% corrette. Tutto ciò che conta è che il modello sia più veloce e preciso di un essere umano.
Ora che abbiamo capito come funziona, passiamo a capire come puoi utilizzare il machine learning nei tuoi prodotti.
Machine Learning: cosa può fare e cosa non può fare

L’hype che ruota attorno all’AI è davvero enorme e molti founder di startup o product manager sognano di aggiungere l’intelligenza artificiale ai propri prodotti. Ma ecco la domanda da un milione di dollari: hai davvero bisogno dell’AI?
Capisco che il termine “AI-driven” (guidato dall’AI) renda bene nel pitch per gli investimenti e nei materiali di marketing di qualsiasi prodotto, ma non dimenticare che sviluppare un modello AI è costoso e richiede tempo.
Di conseguenza, se il tuo modello AI ha lo scopo di risolvere un problema semplice che potresti gestire facilmente con del normale codice, finirai per sprecare le tue risorse solo per avere un termine di moda sul sito web.
Per capire davvero se hai bisogno di un modello AI, analizziamo quali attività e problemi puoi risolvere con esso e confrontiamoli con quelli che dovresti affrontare con la programmazione classica.

Attività comuni che i modelli di machine learning possono svolgere per te
I modelli di ML non sono magie—anche se, con tutti i modi in cui puoi utilizzare ChatGPT e altri recenti large language model, sembra quasi che lo siano. Anche se stiamo assistendo a un boom di strumenti AI evoluti, molti prodotti possono trarre vantaggio da modelli ML più semplici.
Le funzioni che questi modelli eseguono di solito rientrano in quattro categorie.
Classificazione
Come suggerisce il nome, questi modelli sono in grado di riconoscere le informazioni che gli fornisci e di classificarle o assegnare un’etichetta a ciascuna informazione. L’esempio del riconoscimento degli animali nell’immagine di cui abbiamo parlato prima è un caso tipico di classificazione AI.
L’area della classificazione AI a sua volta si suddivide in quattro tipi:
Classificazione binaria: Questo modello ti restituisce un Sì o un No. Gli usi più comuni sono i rilevatori di spam nelle email (isSpam = vero o falso), la diagnosi del tumore al seno (a rischio o non a rischio), ecc.
Classificazione sbilanciata: Questi modelli dividono i dati in due gruppi - una maggioranza normale e una minoranza anomala. Un esempio è la rilevazione delle frodi nelle dichiarazioni doganali alle frontiere di Stato.
Il modello AI analizzerà i documenti e assegnerà bandiere verdi (ok), gialle (necessita controllo dei documenti), o rosse (necessita controllo delle merci) a ciascuna dichiarazione doganale, in base a quanto i documenti sembrano “normali” rispetto agli altri.
Classificazione Multi-Classe: In questo caso, il modello selezionerà uno dei molti valori predefiniti. Gli algoritmi di riconoscimento ottico dei caratteri (quelli che estraggono testo da un'immagine) appartengono a questo tipo.
Classificazione Multi-Etichetta: A differenza della precedente, questi modelli assegneranno più etichette allo stesso dato. Molti algoritmi di visione artificiale rientrano in questa categoria poiché analizzano l'immagine o il video e identificano molteplici oggetti presenti. Ecco come appare la classificazione multi-etichetta per un’auto a guida autonoma.
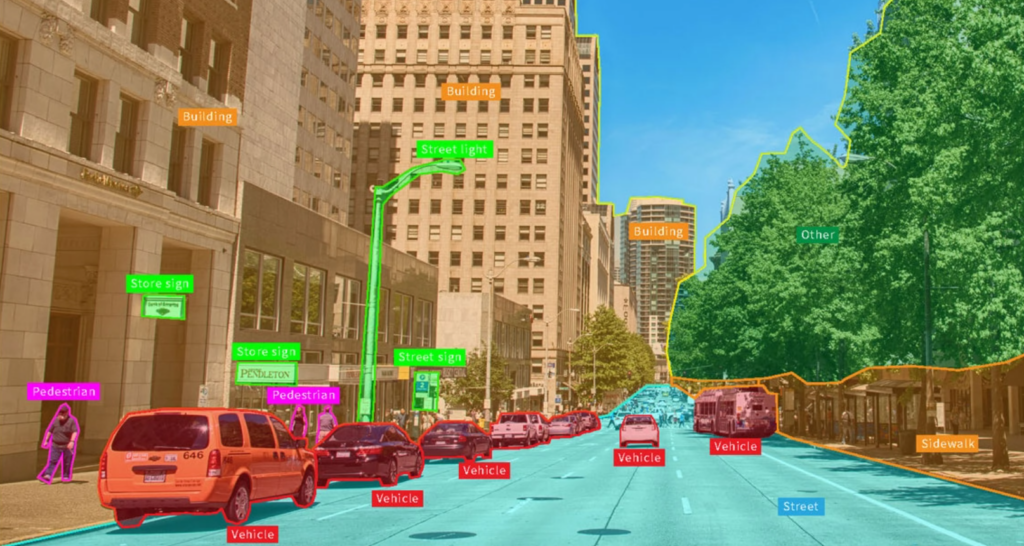
Altre applicazioni di questa tecnologia includono l’estrazione di informazioni utili dai testi (es. opinioni sul tuo marchio dai Tweet) o l’individuazione degli argomenti trattati in un podcast.
Regressione
Questa classe di modelli di intelligenza artificiale è in grado di fare previsioni basandosi su informazioni esistenti. Con i modelli di regressione puoi comprendere la relazione tra diversi fattori e prevedere valori futuri basandoti su quelli del passato (ossia algoritmi di previsione).
Alcuni degli utilizzi degli algoritmi di regressione includono:
- Prevedere il prezzo delle azioni in base alle fluttuazioni passate.
- Prevedere il prezzo di un’auto in base al chilometraggio, anno di produzione, ecc.
- Suggerire i migliori testi pubblicitari per ottenere tassi di conversione più alti.
- Trovare il giorno e l’orario migliori per l’invio di email e ottenere più aperture e clic.
Alcuni dei modelli più avanzati sono anche in grado di prevedere fenomeni complessi e caotici come il meteo.
Clustering
Si tratta di un processo basato sull’apprendimento non supervisionato durante il quale il modello rileva somiglianze in un insieme di elementi e li raggruppa in base alla somiglianza. A differenza della classificazione, un algoritmo di clustering non sa cosa sta vedendo: tutto ciò che sa è che questi elementi sono simili tra loro.
Alcuni casi d’uso per gli algoritmi di clustering sono:
- Raggruppare la tua lista di email marketing in segmenti con comportamenti simili.
- Organizzare una grande raccolta di libri per argomenti.
- Raggruppare le foto in base agli elementi presenti al loro interno.
In generale, se hai un grande insieme di elementi che desideri suddividere in gruppi distinti sulla base di una caratteristica specifica, gli algoritmi di clustering sono ciò che ti occorre.
Sintesi
Infine, abbiamo gli algoritmi capaci di creare contenuti. Parliamo di artisti, scrittori e musicisti artificiali.
I casi d’uso di questa famiglia di modelli sono probabilmente infiniti—e i modelli (ora chiamati large language models, o “LLM”) migliorano ogni giorno. Ecco alcuni esempi:
- Copywriter per siti web che creano struttura e contenuti ottimizzati per la SEO.
- Rimozione della filigrana da un’immagine e disegno della parte coperta dalla filigrana originale.
- Creazione di nuovi frame in un videogioco invece di lasciarli renderizzare dalla scheda grafica per risparmiare risorse.
- Generare foto per le tue campagne pubblicitarie prive di licenza.
Ecco un esempio di una poesia che ho chiesto a GPT-4 di scrivere. (Nota: ho fatto la stessa domanda a GPT-3 a gennaio e ti assicuro che oggi è molto più talentuoso.)

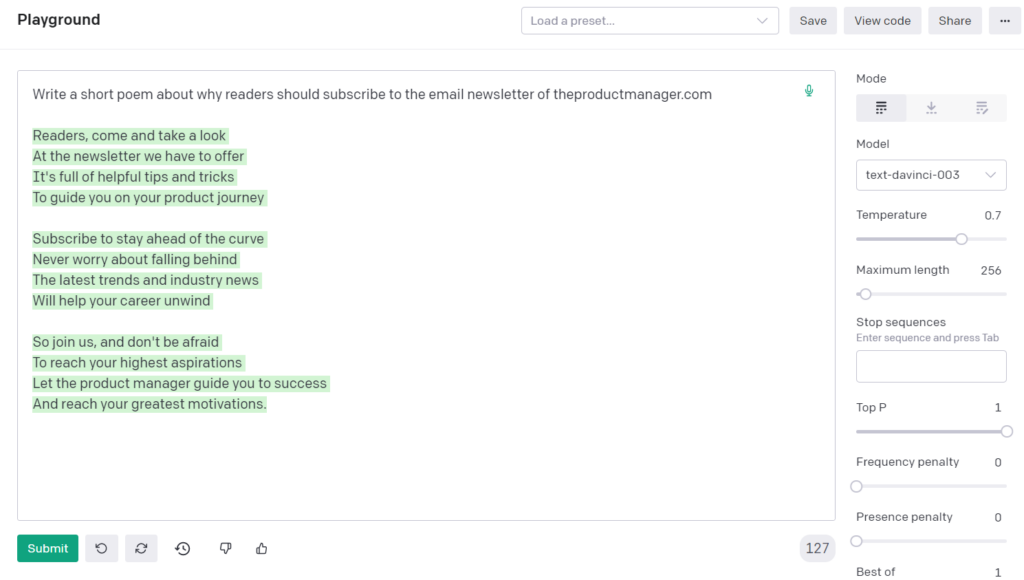
Puoi usare il linguaggio naturale per formulare una richiesta, e il modello comprenderà ed esaudirà la tua domanda in base alle conoscenze acquisite dal web.
In sintesi, questi sono i tipi più comuni di applicazioni dei modelli di intelligenza artificiale.
Sembra che ci siano molte cose che puoi fare con l’AI, ma a volte è più veloce ed economico abbandonare l’idea di costruire un modello e ricorrere allo sviluppo di un semplice software.
Attività dove è meglio usare la programmazione tradizionale
Non ogni problema necessita di un modello di intelligenza artificiale per essere risolto.
Per determinare se puoi risolvere il problema in questione senza IA, chiediti se esiste un insieme deterministico e chiaro di regole o azioni che puoi seguire per risolverlo.
- Se la risposta è sì, allora puoi utilizzare codice tradizionale (dopotutto il codice non è altro che un insieme di regole e comandi chiari per il tuo computer). Ad esempio, non hai bisogno dell’IA per determinare se il file che gli utenti hanno caricato è un foglio di calcolo Excel, poiché i file XLSX hanno una struttura rigida e puoi verificarlo facilmente.
- Quando non riesci a definire queste regole chiare, allora dovrai affidarti a modelli di intelligenza artificiale per gestire quel compito. Un esempio evidente è il riconoscimento delle immagini. Non esiste un insieme affidabile di regole che ti permetta di capire se la cosa rossa in una foto è un’auto di una determinata marca.
Per rafforzare ulteriormente questo concetto, diamo un’occhiata ad alcuni problemi che puoi risolvere senza IA.
Trovare il percorso più breve dal punto A al punto B sulla mappa. Questo è un problema ben noto in matematica e sono disponibili molti approcci deterministici (ad esempio l’algoritmo di Dijkstra) che possono risolverlo con semplice codice tradizionale.
Verificare la presenza di ingorghi sulla mappa. Questo ha una soluzione intelligente. Google, ad esempio, raccoglie dati GPS in tempo reale da tutti gli smartphone (dove questa funzione è attivata) e controlla se ci sono molti telefoni fermi sulla strada. Se accade, probabilmente c’è un ingorgo lì.
Nota: anche se qui è possibile usare l’IA per prevedere un ingorgo in strade dove ci sono pochissimi smartphone o le posizioni sono disperse.
Calcolare le menzioni del marchio sui social media. Se vuoi conoscere il numero di volte in cui il tuo marchio viene menzionato sulle varie piattaforme social, tutto ciò che serve è uno strumento di scraping che legga i risultati delle ricerche sui social e li conteggi.
Nota: un modello di IA qui sarebbe utile per prevedere il numero di menzioni basandosi sull’analisi di una piccola parte dei risultati (invece di tutta la lista) — facendoti risparmiare potenza di calcolo e risorse.
In conclusione, i modelli di intelligenza artificiale sono assai capaci per i compiti che possono svolgere, ma a volte è semplicemente più semplice programmare una soluzione tradizionale.
Ora che hai compreso come utilizzare l’Intelligenza Artificiale nei tuoi prodotti, passiamo a condividere alcuni suggerimenti per lavorare con i modelli di IA.
6 consigli per product manager che lavorano con il Machine Learning
Durante la mia carriera lavorando con prodotti di machine learning, ho commesso molti errori che hanno comportato una perdita di tempo e denaro. Per fare in modo che tu, come product manager di ML, non ripeta questi errori, ecco alcuni suggerimenti utili da considerare.
La qualità dei dati determinerà il successo o il fallimento dei tuoi modelli
I team di ML Engineering e i Data Scientist amano usare l’espressione “garbage in - garbage out.” Significa che la qualità del modello dipenderà direttamente dalla qualità dei dataset che usi per addestrarlo.
Per capire cosa intendo con dati scadenti, vediamo insieme alcuni aspetti che ne determinano la qualità:
Cattive annotazioni: L’annotazione è il processo di etichettatura manuale dei nuovi dati per usarli come “risultati corretti” nell’addestramento del tuo modello. Gli annotatori di un modello che riconosce gli animali, ad esempio, evidenzieranno la creatura nell’immagine e la etichetteranno con il suo nome. Se etichetti gli elefanti come “pinguini”, anche il tuo modello farà lo stesso dopo l’addestramento.
Mancanza di diversità: i tuoi modelli funzioneranno bene solo se i dati del mondo reale sono simili a quelli su cui sono stati addestrati. Se hai un sistema di rilevamento targhe che ha imparato a leggere solo le targhe americane, fallirà miseramente quando vedrà un’auto con targhe europee.
Bias nei dati: Hai mai sentito parlare di IA razzista? Di recente Google si è scusata con la comunità afroamericana perché il suo algoritmo di visione artificiale ha fatto questo:
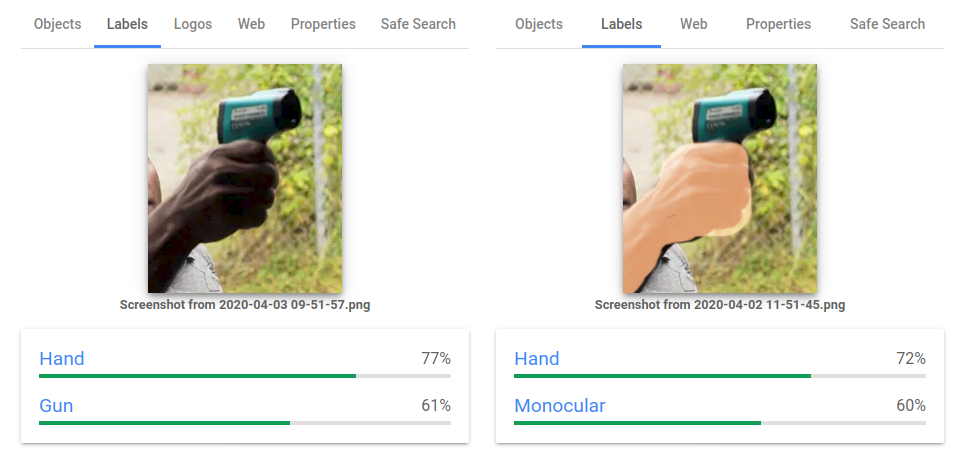
Ci sono anche numerosi casi di modelli di IA usati dalle forze dell’ordine che prendono di mira le minoranze.
La ragione di ciò è il bias nei dati. Questi sistemi di IA delle forze dell’ordine hanno utilizzato database di commissariati noti per discriminazioni razziali. Di conseguenza, c’erano molti dati sugli arresti di minoranze che hanno indotto i modelli a prenderli di mira.
Quindi assicurati che i dati che utilizzi non contengano pregiudizi che possano portare a mancanza di rispetto, offese, o peggio.
Crea funzionalità che ti permettano di riaddestrare i tuoi modelli
Costruire i modelli è solo metà del lavoro—devi anche migliorarli costantemente aggiungendo nuove capacità o semplicemente fornendo nuovi dati su cui riaddestrarli.
Trovare dati pertinenti per il retraining del tuo prodotto ML può essere una sfida. Quindi, considera di aggiungere funzionalità che ti permettano di ottenere tali dati direttamente dal prodotto stesso.
Ecco due approcci di feedback loop che ho provato (e che hanno funzionato bene):
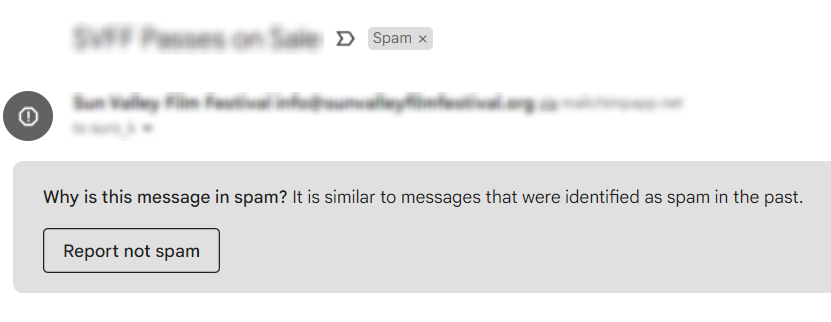
Richiedere un feedback sui risultati dell’IA: Se stai rilevando spam nelle email, allora aggiungi un pulsante “non è spam” per consentire agli utenti di rimuovere l’email dallo spam. Come conseguenza di questa azione, annoteranno anche quell’email come non-spam e tu potrai usarla per il retraining del modello.
Nota: Sì, è esattamente ciò che fa il pulsante “Segnala non spam” in Gmail.
Offrire all'utente la possibilità di ottimizzare il tuo modello sui propri dati: Questa è una situazione vantaggiosa per entrambi. I tuoi utenti avranno un modello più performante perché l’avrai riaddestrato sui loro dati specifici e tu otterrai dati aggiuntivi per aumentare la diversità del tuo modello.
Se puoi, utilizza soluzioni già pronte invece di crearne una da zero
Non devi reinventare la ruota dell’IA. Esistono molti modelli già pronti che puoi acquistare o noleggiare. Questo è particolarmente rilevante se stai cercando di risolvere un problema abbastanza comune (ad esempio, identificare immagini di nudo nella tua app di social media).
Puoi trovare modelli già pronti su piattaforme come Modelplace e RapidAPI Hub.
Una semplice ricerca di un modello per il rilevamento dei loghi ci ha portato a 9 soluzioni già pronte che possiamo integrare tramite API.
Usa (e contribuisci a) modelli di IA open source
L’intelligenza artificiale ha una comunità open source molto attiva. Puoi fare affidamento su di essa per trovare modelli già pronti o strumenti utili per aiutarti nella costruzione dei tuoi modelli.
Puoi consultare questa lista su GitHub per alcuni dei migliori progetti e iniziative di machine learning open source disponibili. Questa lista è piuttosto varia e include:
- Modelli con diversi livelli di spiegabilità (quanto bene puoi spiegare il funzionamento del tuo modello) scritti in Python e C da giganti come IBM e Amazon.
- Dati di addestramento per i tuoi modelli.
- Strumenti per analisi dei dati, monitoraggio delle metriche chiave, rilevamento delle anomalie e altro.
Nota: Se hai apportato miglioramenti a questi modelli, apri una pull request e condividi il tuo lavoro con la comunità open source e i suoi stakeholder. L’open source riguarda persone straordinarie che fanno cose straordinarie e le condividono con gli altri.
I modelli di IA richiedono tempo per essere costruiti
Le metodologie Agile e MVP non funzionano sempre con i sistemi di machine learning. Non puoi sempre costruire un modello piccolo e poi aggiungere nuove funzionalità sopra con molte iterazioni. A volte basta una piccola modifica al modello per doverlo riaddestrare da zero.
Potresti persino trovarti in una situazione in cui ottimizzare il tuo modello del 10% significhi abbandonare quello vecchio e crearne uno nuovo di machine learning.
Un’altra cosa da considerare è la specificità del lavoro dei professionisti dei dati o dei team trasversali che li includono.
A volte non saranno in grado di darti stime su quando completeranno il loro lavoro, dato che trascorrono la maggior parte del tempo a inventare qualcosa di completamente nuovo e non hanno idea di quanto il processo di sviluppo potrà richiedere. (Un ottimo esempio di questo è la timeline incerta del rilascio di Google Gemini.)
Evita cambiamenti drastici nella struttura del tuo database
Questa è una realtà dolorosa che mi è capitato di affrontare un paio di volte.
Se usi dati proprietari per riaddestrare i tuoi modelli, per favore evita di cambiare la struttura del tuo database.
I tuoi modelli saranno progettati per consumare dati di una struttura e di un tipo specifici, e se il tuo team di data engineering cambia i tuoi database, il team ML dovrà modificare i modelli o persino riaddestrarli da zero.
Imparare è un processo continuo.
L’intelligenza artificiale ha reso il mondo un posto migliore per tutti noi, permettendo a tanti founder visionari e ai PM di ML di risolvere problemi che in passato sembravano impossibili.
Spero che questa guida ti abbia aiutato a comprendere il concetto di IA nella gestione del prodotto, il ruolo del product manager in questo processo, così come i modi reali in cui le aziende possono utilizzare l'IA.
Ma creare ottimi nuovi prodotti non riguarda solo il corretto utilizzo dell’IA. Ci sono molti altri aspetti importanti del prodotto che dovresti padroneggiare, tra cui:
- L'arte di costruire Prodotti Minimi Funzionanti.
- Pianificare correttamente il lavoro del tuo team con le Roadmap di Prodotto.
- Trovare il tuo PMF in modo economico, ecc.
Infine, come suggeriva la poesia nella demo di GPT-3, puoi iscriverti alla nostra newsletter per ricevere il meglio della gestione del prodotto e rimanere sempre un passo avanti.

{kind=link}