L’apprentissage automatique pour les chefs de produit : Un cours accéléré essentiel

L’intelligence artificielle est probablement le sujet le plus brûlant dans le monde de la technologie actuellement.
On voit des produits pilotés par l’IA devenir des licornes ou obtenir des centaines de millions de dollars en financement de capital-risque. Il y a aussi des leaders de produit célèbres qui dirigent ces produits basés sur l’IA, que nous suivons et dont nous apprenons.
De nombreux chefs de produit souhaitent profiter de cette incroyable technologie en dirigeant un produit IA ou en ajoutant des fonctionnalités d’IA à leurs produits existants. Si vous en faites partie, cet article est pour vous.
J’ai construit plusieurs produits IA, et je suis là pour vous aider à comprendre cette technologie et à en tirer le meilleur parti.
Qu’est-ce que l’apprentissage automatique ?
L’apprentissage automatique est une discipline qui se concentre sur la création d’algorithmes et de logiciels capables de “lire” les informations que nous fournissons et d’effectuer efficacement certains types de tâches à la suite de cet entraînement.
Le terme et le domaine eux-mêmes sont étonnamment anciens—ils remontent à 1959, lorsque Arthur Samuel d’IBM (l’un des scientifiques informaticiens éminents de l’époque) l’a nommé dans ses travaux « Some Studies in Machine Learning Using the Game of Checkers. »
Malgré ses 60 ans d’existence, cependant, l’apprentissage automatique n’est devenu populaire que depuis une dizaine d’années grâce à l’augmentation massive de la puissance de calcul, notamment au niveau des GPU.
Mais quel est le lien entre l’apprentissage automatique et l’intelligence artificielle ? Avançons pour clarifier cela.
Apprentissage automatique (ML) vs Intelligence artificielle (AI)
Tout le monde utilise les termes « apprentissage automatique » et « intelligence artificielle » de manière interchangeable pour désigner un logiciel intelligent capable de reconnaître des objets sur des images, d’écrire des poèmes et de générer des réponses impressionnantes à des requêtes détaillées.
Cependant, l’intelligence artificielle est le concept général de machines dotées de capacités de perception et de raisonnement, alors que l’apprentissage automatique est un sous-ensemble de l’IA qui se concentre sur les logiciels capables d’apprendre.
Maintenant que nous avons défini ces termes, passons à la compréhension de la manière dont ces machines apprennent et des principes essentiels de leur fonctionnement.
Comment fonctionne l’apprentissage automatique

Pour comprendre l’apprentissage automatique, il nous faut d’abord examiner sa forme la plus courante : les réseaux neuronaux profonds.
Un réseau neuronal est une structure écrite en code classique qui tente de reproduire le fonctionnement d’un cerveau biologique. Pour les humains et les autres êtres vivants, le cerveau est un réseau complexe de neurones (cellules nerveuses) connectés entre eux, où une impulsion d’une cellule active une autre, et l’information circule le long de ce réseau de neurones.
Je ne pense pas être la meilleure personne pour expliquer la biologie (car j’y échouerais lamentablement), donc je vais m’en tenir à la technologie.
Les réseaux neuronaux en logiciel ressemblent à ceci :
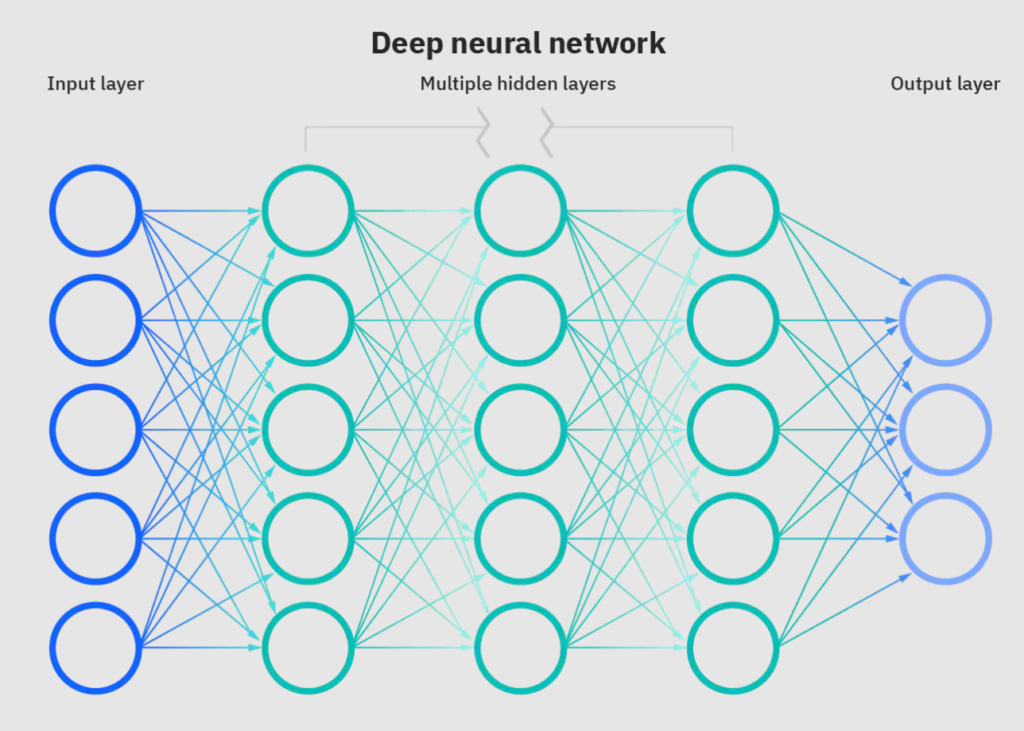
Chaque cercle ici est un neurone individuel. En code, un neurone est simplement une fonction qui peut consommer une certaine information, la traiter et transmettre un résultat au neurone suivant.
Remarque : il s’agit ici d’une simplification du processus réel. Pour plus de détails, vous pouvez regarder l’excellente vidéo pédagogique sur les réseaux neuronaux sur la chaîne YouTube 3blue1brown, où ils expliquent également les concepts mathématiques derrière cette technologie.
Comme on peut le voir sur l’image ci-dessus, nos neurones sont organisés en couches. Les réseaux neuronaux comprennent généralement trois types de couches :
- La couche d’entrée, qui est chargée de recevoir l’information en provenance du monde extérieur.
- Les couches cachées traitent cette information, chacune d’elles traitant un aspect distinct.
- La couche de sortie va renvoyer le résultat traité à l’extérieur.
Comprenons maintenant le rôle de ces couches à l’aide d’un exemple simple. Imaginez que vous voulez que le réseau neuronal reconnaisse un animal sur une photo. Pour cela, vous avez conçu un réseau neuronal composé de six couches qui fonctionneront de la manière suivante :
- Couche d'entrée qui prendra de petits segments de la photo de l'animal et les transmettra à la première couche cachée.
- La première couche cachée essaiera de trouver des formes basiques (par exemple, des lignes droites) dans chaque segment et transmettra cette information à la seconde couche.
- La deuxième couche combinera alors certaines de ces lignes en formes géométriques simples (par exemple, des cercles, des demi-cercles, etc.) et les transmettra à la troisième couche.
- La troisième couche créera alors des formes plus complexes à partir de ces structures géométriques.
- La quatrième couche combinera toutes les formes créées auparavant pour obtenir un contour de l'animal.
- Enfin, la couche de sortie indiquera le type d'animal qu'elle a reconnu à partir de la forme.
Voici à quoi cela ressemblera visuellement.
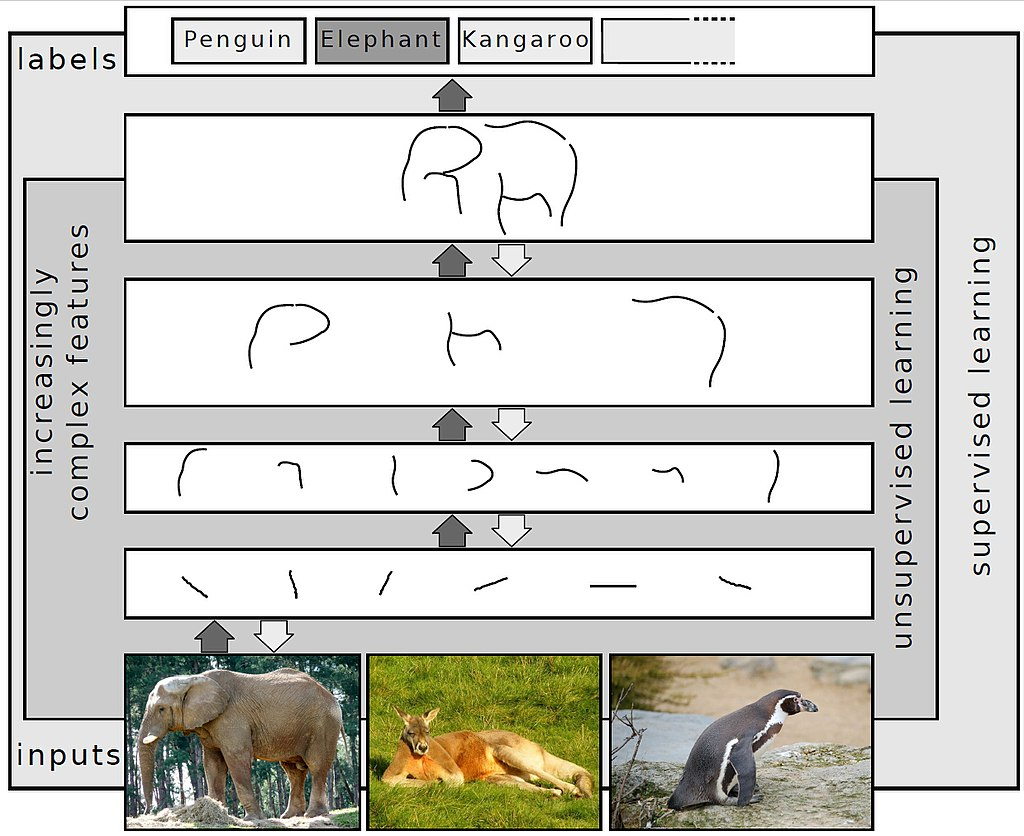
En regardant le processus ci-dessus, vous vous demandez peut-être comment les ingénieurs en IA font en sorte que ces couches reconnaissent les formes et devinent l’animal de l’image, n’est-ce pas ? Eh bien, ils y parviennent en « entraînant » le réseau neuronal à accomplir sa tâche.
Pour entraîner le réseau, les ingénieurs en IA lui fournissent un ensemble d’entrées accompagnées de leurs sorties correctes correspondantes. Dans notre cas, il s’agirait de plusieurs images d’animaux en entrées, et ces mêmes images avec le bon type d’animal en sorties.
Comme votre réseau possède les bonnes réponses, il va continuellement s’ajuster (en modifiant les paramètres que chaque neurone transmet aux autres) jusqu’à ce que ses réponses soient très proches de celles que nous avons fournies.
Dans la réalité, votre réseau ne sera jamais précis à 100% dans ses réponses et il y aura toujours une certaine marge d’erreur à prendre en compte. La bonne nouvelle, c’est que vous ne voulez pas forcément qu’ils soient à 100% corrects. Tout ce qui compte, c’est que le modèle soit plus rapide et précis qu’un humain.
Maintenant que nous avons compris comment cela fonctionne, passons à la façon dont vous pouvez intégrer l’apprentissage automatique dans vos produits.
Apprentissage automatique : ce qu’il peut faire et ce qu’il ne peut pas faire

L’engouement autour de l’IA est absolument énorme, et de nombreux fondateurs de startup ou chefs de produit rêvent d’ajouter de l’IA à leurs produits. Mais voici la question à un million de dollars : avez-vous vraiment besoin de l’IA ?
Je comprends que l’expression « piloté par l’IA » ait fière allure dans un pitch pour investisseurs ou dans les supports marketing, mais n’oubliez pas que construire un modèle d’IA coûte cher et prend du temps.
Ainsi, si votre modèle IA vise à résoudre un problème fondamental que vous auriez pu facilement traiter avec du code classique, vous gaspillerez vos fonds pour un terme tape-à-l’œil sur votre site web.
Pour comprendre votre besoin d’un modèle IA, discutons des tâches et des problèmes que vous pouvez lui confier et comparons-les à ceux qu’il vaut mieux résoudre par de la programmation traditionnelle.
Tâches courantes que les modèles d’apprentissage automatique peuvent gérer pour vous
Les modèles d’apprentissage automatique ne sont pas magiques — même si, avec toutes les manières d’utiliser ChatGPT et autres nouveaux grands modèles de langage, cela en donne l’impression. Alors qu’une vague d’outils IA avancés déferle, de nombreux produits peuvent bénéficier de modèles d’apprentissage automatique plus simples.
Les fonctions assurées par ces modèles se classent généralement en quatre grandes catégories.
Classification
Comme son nom l’indique, ces modèles sont capables de reconnaître les informations que vous leur fournissez et de les classifier ou de leur attribuer une étiquette. L’exemple de reconnaissance d’animaux à partir d’une image que nous avons évoqué précédemment est un cas typique de classification IA.
La classification IA se décline elle-même en quatre types :
Classification binaire : Ce modèle vous donne une réponse Oui ou Non. Les cas d’usage fréquents sont les filtres anti-spam d’email (isSpam = vrai ou faux), le diagnostic du cancer du sein (risqué ou non risqué), etc.
Classification déséquilibrée : Ces modèles divisent les données en deux groupes – une majorité normale et une minorité anormale. Par exemple, la détection de fraude dans les déclarations douanières aux frontières d’un État.
Le modèle IA examinera les documents et attribuera à chaque déclaration douanière un drapeau vert (bon à passer), jaune (nécessite une inspection des documents), ou rouge (nécessite une inspection des marchandises), selon le degré de « normalité » des documents par rapport aux autres.
Classification multi-classes : Dans ce cas, le modèle va sélectionner l'une des nombreuses valeurs prédéfinies. Les algorithmes de reconnaissance optique de caractères (ceux qui extraient du texte depuis une image) appartiennent à cette catégorie.
Classification multi-étiquettes : Contrairement au précédent, ces modèles vont attribuer plusieurs étiquettes à la même donnée. De nombreux algorithmes de vision par ordinateur entrent dans cette catégorie puisqu'ils analysent une image ou une vidéo et identifient plusieurs objets à l'intérieur. Voici à quoi ressemble une classification multi-étiquettes pour une voiture autonome.
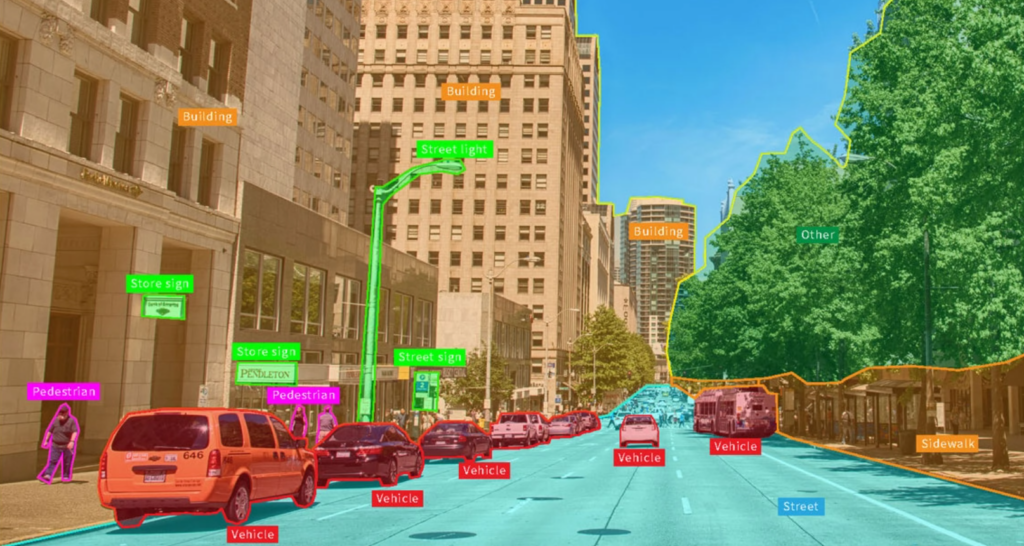
Parmi les autres applications de cette technologie, on trouve l'extraction d'informations utiles à partir de textes (par exemple, les avis sur votre marque à partir de Tweets) ou l'identification des sujets abordés dans un podcast.
Régression
Cette classe de modèles d'IA est capable de faire des prédictions à partir d'informations existantes. Avec les modèles de régression, vous pouvez comprendre la relation entre plusieurs facteurs ainsi que prédire des valeurs futures à partir de celles du passé (également appelé algorithmes de prévision).
Quelques utilisations des algorithmes de régression incluent :
- Prédire le cours d'une action en fonction des fluctuations passées.
- Prédire le prix d'une voiture en fonction du kilométrage, de l'année de production, etc.
- Suggérer les meilleurs textes publicitaires pour de meilleurs taux de conversion.
- Déterminer le meilleur jour de la semaine et l'heure pour envoyer des emails afin d’obtenir le plus d’ouvertures et de clics.
Certains des plus grands modèles peuvent aussi prédire des choses aussi complexes et chaotiques que la météo.
Regroupement (Clustering)
Il s’agit d’un processus basé sur l’apprentissage non supervisé, où le modèle détecte des similarités dans un ensemble d’éléments et les regroupe en fonction de cette similarité. Contrairement à la classification, un algorithme de regroupement ne sait pas ce qu'il observe, il sait seulement que ces éléments se ressemblent.
Quelques exemples d’utilisation des algorithmes de regroupement :
- Segmenter une liste d'emails marketing en groupes de comportements similaires.
- Classer un grand ensemble de livres par thématiques.
- Rassembler des photos selon les objets détectés dessus.
En général, si vous disposez d’un ensemble important d’éléments à répartir en groupes distincts selon une caractéristique spécifique, les algorithmes de regroupement sont ce qu’il vous faut.
Synthèse
Enfin, nous avons les algorithmes capables de générer du contenu. On parle ici d’IA artistes, écrivains et musiciens.
Les cas d’utilisation de ce groupe de modèles semblent probablement sans fin—et les modèles (désignés aujourd’hui comme des grands modèles de langage, ou « LLMs ») progressent chaque jour. Voici quelques exemples :
- Rédacteurs web générant la structure et le contenu optimisés pour le référencement.
- Supprimer le filigrane d’une image et dessiner la partie de l’image qui se trouvait sous ce filigrane.
- Créer de nouvelles images d’un jeu vidéo au lieu de laisser la carte graphique les rendre, afin d’économiser des ressources.
- Générer des photos libres de droits pour vos publicités.
Voici un exemple de poème que j'ai demandé à GPT-4 d’écrire. (Remarque : J’ai posé la même question à GPT-3 en janvier, et je vous assure qu’il est aujourd’hui nettement plus talentueux.)

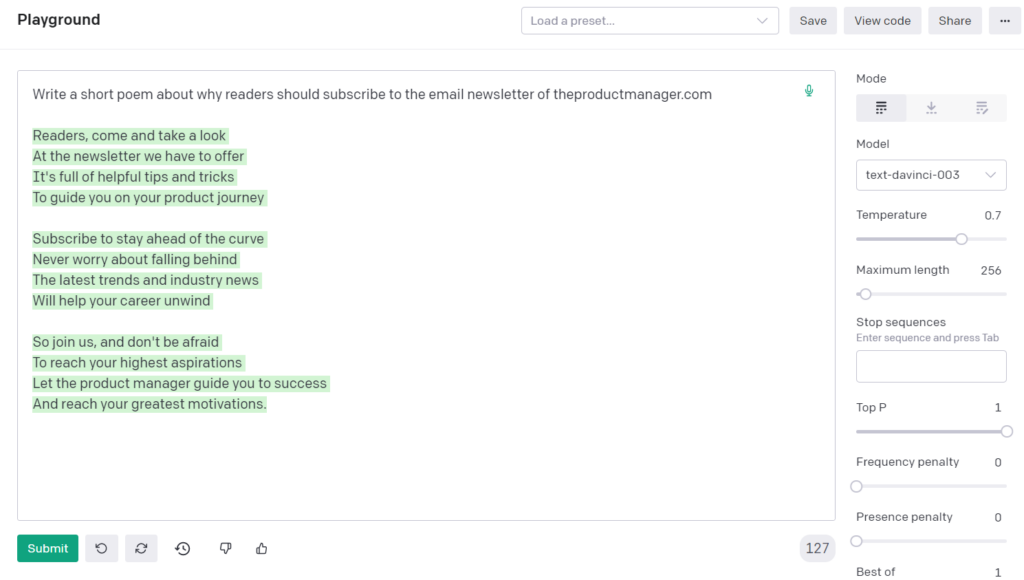
Vous pouvez utiliser le langage naturel pour formuler une requête, et le modèle comprendra et réalisera votre demande grâce aux connaissances accumulées sur internet.
Pour résumer, voici les types d’applications de modèles d’IA les plus fréquents.
Il semble qu’il existe beaucoup de choses possibles avec l’IA, mais parfois il est plus rapide et économique de renoncer à l’idée de construire un modèle, et de se tourner vers le développement logiciel classique.
Tâches pour lesquelles il vaut mieux utiliser du codage traditionnel
Chaque problème n'a pas besoin d'un modèle d'IA pour être résolu.
Pour déterminer si vous pouvez résoudre le problème sans IA, demandez-vous s'il existe un ensemble déterministe et clair de règles ou d'actions à suivre pour le solutionner.
- Si la réponse est oui, vous pouvez utiliser un code classique (après tout, le code n'est qu'un ensemble de règles précises et de commandes pour votre ordinateur). Par exemple, vous n'avez pas besoin d'IA pour déterminer si le fichier que vos utilisateurs ont téléchargé est une feuille de calcul Excel, car les fichiers XLSX ont une structure stricte que vous pouvez vérifier.
- Lorsque vous ne pouvez pas énoncer ces règles claires, vous devrez alors vous appuyer sur des modèles d'IA pour accomplir cette tâche à votre place. L'exemple évident ici est la reconnaissance d'image. Il n'existe aucun ensemble de règles fiable qui permet de savoir si la chose rouge sur la photo est une voiture d'une marque spécifique.
Pour renforcer ce concept, examinons quelques problèmes que vous pouvez résoudre sans IA.
Trouver l’itinéraire le plus court du point A au point B sur la carte. Il s'agit d'un problème bien connu en mathématiques et il existe de nombreuses approches déterministes (par exemple, l’algorithme de Dijkstra) qui peuvent le résoudre avec un simple code.
Vérifier les embouteillages sur la carte. Ici, la solution est astucieuse. Par exemple, Google utilise les données GPS en temps réel de tous les smartphones (lorsque la fonctionnalité est activée) et vérifie si de nombreux téléphones sont immobiles sur une route. Si c'est le cas, cela signifie qu’il y a sûrement un embouteillage à cet endroit.
Remarque : Bien sûr, vous pouvez utiliser l’IA ici pour prédire un embouteillage sur une route où il y a très peu de smartphones ou lorsque les localisations sont dispersées.
Calcul du nombre de mentions de la marque sur les réseaux sociaux. Si vous souhaitez connaître le nombre de fois que votre marque est mentionnée sur les réseaux sociaux, il vous suffit d'utiliser un outil de scraping qui lira les résultats de recherche sociaux et les comptera.
Remarque : Un modèle d’IA serait ici utile pour prédire le nombre de mentions basé sur une toute petite partie des résultats (plutôt que sur l'intégralité de la liste des résultats de recherche), ce qui permettrait d'économiser des ressources et de la puissance de calcul.
En résumé, les modèles d’IA sont très performants pour de nombreuses tâches, mais parfois il est plus simple de simplement coder la solution.
Maintenant que vous comprenez comment intégrer l'Intelligence Artificielle dans vos produits, je vais vous donner quelques conseils pour travailler avec les modèles d’IA.
6 conseils pour les chefs de produit travaillant avec l'apprentissage automatique
Au cours de ma carrière avec des produits d'apprentissage automatique, j'ai fait de nombreuses erreurs qui m'ont fait perdre du temps et de l'argent. Pour que vous, chefs de produit ML, ne répétiez pas ces erreurs, voici quelques conseils utiles à garder à l’esprit.
La qualité des données fera la réussite ou l’échec de vos modèles
Les équipes d’ingénierie ML et les data scientists aiment utiliser le terme « poubelle en entrée – poubelle en sortie ». Cela signifie que la qualité du modèle dépendra directement de la qualité des jeux de données que vous utilisez pour l’entraîner.
Pour comprendre ce que j'entends par « mauvaises données », laissez-moi détailler quelques aspects qui en déterminent la qualité :
Mauvaises annotations : L’annotation est le processus qui consiste à étiqueter manuellement de nouvelles données pour servir de « résultats corrects » à l’entraînement de votre modèle. Par exemple, les annotateurs d’un modèle qui reconnaît les animaux vont surligner la créature sur l’image et lui donner son nom. Si vous étiquetez les éléphants comme « pingouins », après l’entraînement votre modèle fera la même erreur.
Manque de diversité : Vos modèles ne fonctionneront correctement que si les données du monde réel ressemblent à celles sur lesquelles ils ont été entraînés. Si vous avez un système de lecture de plaques d’immatriculation qui n’a appris qu’avec des plaques américaines, il échouera lamentablement lorsqu’il verra une voiture avec une plaque européenne.
Biais dans les données : Avez-vous déjà entendu parler d'une IA raciste ? Google a récemment présenté ses excuses à la communauté afro-américaine car son algorithme de vision par ordinateur avait produit ce résultat :
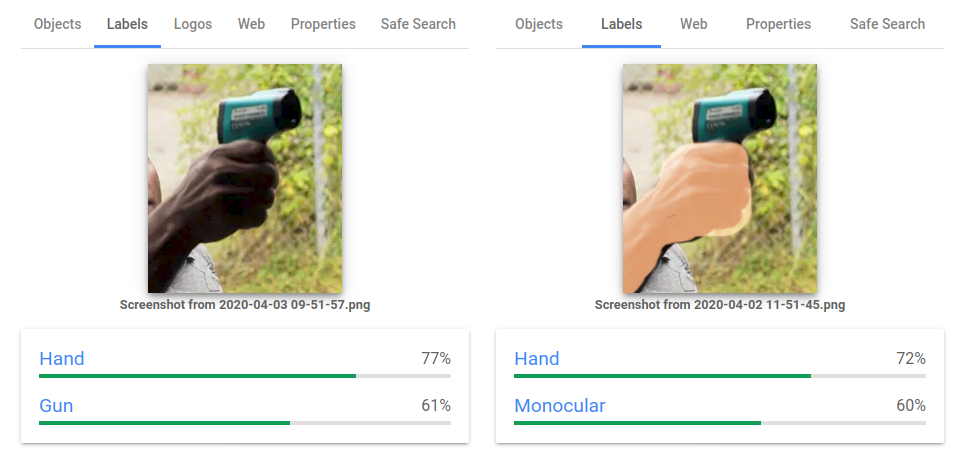
Il existe également de nombreux cas de modèles d’IA utilisés par la police qui visent principalement les minorités.
La raison derrière cela est le biais dans les données. Ces IA policières utilisaient la base de données d’un commissariat connu pour être raciste. Par conséquent, il y avait beaucoup de données sur les arrestations de personnes issues de minorités, ce qui a conduit le modèle à les cibler.
Veillez donc à ce que les données que vous utilisez ne comportent pas de biais pouvant entraîner un manque de respect, des offenses, voire pire.
Construisez des fonctionnalités qui vous aident à réentraîner vos modèles
Créer des modèles n’est que la moitié du travail — il vous faut également l’améliorer en continu en lui ajoutant de nouvelles capacités ou simplement en lui fournissant des données récentes pour le réentraîner.
Il peut être difficile de trouver des données pertinentes pour la remise à niveau de votre produit ML. Pensez donc à ajouter des fonctionnalités qui vous permettront d'obtenir ces données directement via le produit lui-même.
Voici deux approches de boucle de rétroaction que j'ai testées (et qui ont très bien fonctionné) :
Demander des retours sur les résultats de l’IA : Si vous détectez du spam dans les e-mails, ajoutez alors un bouton « pas du spam » permettant aux utilisateurs de retirer un e-mail du dossier spam. Ce faisant, ils "annotent" également ce message comme n'étant pas du spam et vous pouvez l'utiliser pour réentraîner votre modèle.
Remarque : Oui, c'est exactement ce que fait le bouton « Signaler comme non-spam » dans Gmail.
Proposer à l’utilisateur d’affiner votre modèle à partir de ses données : C’est une situation gagnant-gagnant. Vos utilisateurs bénéficieront d’un modèle mieux adapté, car vous l’aurez réentraîné avec leurs données spécifiques, tandis que vous récupérerez des données supplémentaires pour augmenter la diversité de votre modèle.
Si possible, utilisez des solutions prêtes à l’emploi plutôt que d’en développer une vous-même
Vous n’êtes pas obligé de réinventer la roue de l’IA. Il existe de nombreux modèles prêts à l’emploi que vous pouvez acheter ou louer. Cela est particulièrement pertinent si vous cherchez à résoudre un problème assez commun (par exemple, l’identification d’images dénudées sur une application de réseaux sociaux).
Vous pouvez retrouver des modèles prêts à l’emploi sur des plateformes telles que Modelplace et RapidAPI Hub.
Une simple recherche d’un modèle de détection de logos nous a proposé 9 solutions prêtes à l’intégration via API.
Utilisez (et contribuez à) des modèles d’IA open-source
L’intelligence artificielle possède une communauté open source importante. Vous pouvez vous appuyer dessus pour trouver des modèles prêts à l’emploi ou des outils utiles afin de construire les vôtres.
Vous pouvez consulter cette liste sur GitHub pour découvrir certains des meilleurs projets et initiatives open-source en apprentissage automatique. Cette liste est assez variée et comprend :
- Des modèles avec différents niveaux d’explicabilité (le degré auquel vous pouvez expliquer le fonctionnement de votre modèle) écrits en Python et C par des géants comme IBM et Amazon.
- Des jeux de données d’entraînement pour vos modèles.
- Des outils pour l’analyse des données, le suivi de métriques clés, la détection d’anomalies, et plus encore.
Remarque : si vous avez amélioré ces modèles, merci d’ouvrir une pull request afin de partager votre travail avec la communauté open-source et ses parties prenantes. L’open source consiste en des gens formidables qui font des choses extraordinaires et les partagent avec les autres.
Les modèles d’IA prennent du temps à construire
Les méthodologies Agile et MVP ne fonctionnent pas toujours avec les systèmes ML. Il n’est pas toujours possible de construire un petit modèle puis d’ajouter de nouvelles fonctionnalités au fil des itérations. Parfois, une modification légère du modèle nécessitera de le réentraîner entièrement.
Il peut même arriver qu’optimiser votre modèle de 10% signifie devoir abandonner l’ancien pour en créer un nouveau, avec un autre algorithme d’apprentissage automatique.
Un autre point à prendre en compte est la spécificité du travail des professionnels de la data science ou des équipes transverses qui en disposent.
Parfois, ils ne pourront pas vous donner d'estimation sur la date d’achèvement de leur travail, car ils passent la majorité de leur temps à inventer quelque chose de réellement nouveau, sans pouvoir prévoir combien de temps la phase de développement leur prendra. (Un bon exemple est le calendrier hésitant de la sortie de Google Gemini.)
Évitez les changements drastiques dans la structure de votre base de données
C’est une réalité douloureuse à laquelle j’ai été confronté à plusieurs reprises.
Si vous utilisez vos propres données pour réentraîner vos modèles, abstenez-vous de modifier la structure de votre base de données.
Vos modèles sont conçus pour consommer des données d’une structure et d’un type spécifiques et, si votre équipe de data engineering modifie vos bases de données, votre équipe ML devra changer ses modèles, voire les réentraîner complètement.
L’apprentissage est un processus continu.
L’intelligence artificielle a amélioré la vie de tous, car elle a permis à de nombreux fondateurs visionnaires et chefs de produit ML de résoudre des problèmes qui paraissaient autrefois impossibles.
J’espère que ce guide vous a aidé à comprendre le concept de l’IA dans la gestion de produit, le rôle du chef de produit dans ce processus, ainsi que les applications concrètes permettant aux entreprises d’utiliser l’IA.
Mais créer d’excellents nouveaux produits ne dépend pas seulement d’une bonne utilisation de l’IA. Il existe de nombreux aspects importants du produit que vous devriez maîtriser, notamment :
- L’art de construire un Produit Minimum Viable.
- Planifier correctement le travail de votre équipe avec des feuilles de route produit.
- Trouver votre product-market fit (PMF) de manière économique, etc.
Enfin, comme le suggère le poème dans la démonstration GPT-3, vous pouvez vous abonner à notre newsletter pour recevoir le meilleur de la gestion de produit et garder une longueur d’avance.

{kind=link}